单倍型基因组组装工具 --- Trio binning
Introduction
大多数基因组组装工具只是简单的将单倍型共同组装成一个 mosaic consensus,从而导致组装不能准确地代表任何一个原始单倍型。将单倍型折叠成一个单一的 consensus 会引入不存在于任何一单倍型中的错误变体,从而导致注释或分析错误。在理想情况下,基因组应该表示为一组完整的单倍型,而不是 artificial mixture。解决这种问题的常见方法就是对近交个体进行测序来减少单倍型变异的问题,然而,这对许多物种来说时不切实际的;即使在可能的情况下,也可能导致基因组不能代表自然种群中发现的变异。另一种方法是使用单倍体、基于克隆的基因组库,就像人类基因组计划所做的那样。
依赖于参考基因图谱的方法在高杂合性/单倍型之间存在大量结构变异的区域表现较差。
二倍体组装问题更全面的解决方案是将单倍型分离整合到组装过程本身中。然而,这种方法受限于测序的 reads 长度。单独的测序 reads 并不总是包含足够的信息来连接较长纯合子区域的变体,从而导致相对较短的 phase blocks。作为折中的办法 Falcon phase 和 Supernova 输出代表每个位置的单个等位基因的 伪单倍型,但不保留长等位基因或组装 gaps。此外,这些组装程序可能将重复与发散的等位基因混淆,从而导致人为重复或缺失。一种可能的解决方案是将 long reads 测序与其他类型的信息相结合。如 linked reads、bacterial artificial chromosomes(BACs)、Strand-seq、Hi-C。
pseudo-haplotypes:伪单倍型
assembly gaps:组装间隙
Trio binning 为二倍体组装问题提供了一个简单的解决方案,从而组装准确的基因组规模的单倍型,与其他仅限于对单个染色体进行定相的方法不同,最终可产生两个完整的单倍型基因组 — 分属两个亲本单倍型。这些完整的单倍型是通用的,可以单独分析或通过比对重组成二倍体基因组图。
Trio binning是一种通过在组装前解决等位基因变异来简化单倍型组装的方法,组装准确性随着杂合度的增加而提高。根据来自两个亲本基因组的
short reads来将来自子代的long reads划分为特定于单倍型的集合,然后对每个单倍型进行独立组装,从而形成完整的二倍体重建。
Trio binning 在组装之前使用 父本-母本-后代 三人组分离单倍型是关键,由于是在组装前提前将子代的 reads 分成两个单倍型进行分别组装,所以不受单倍型间变异的干扰。
Trio binning 组装策略
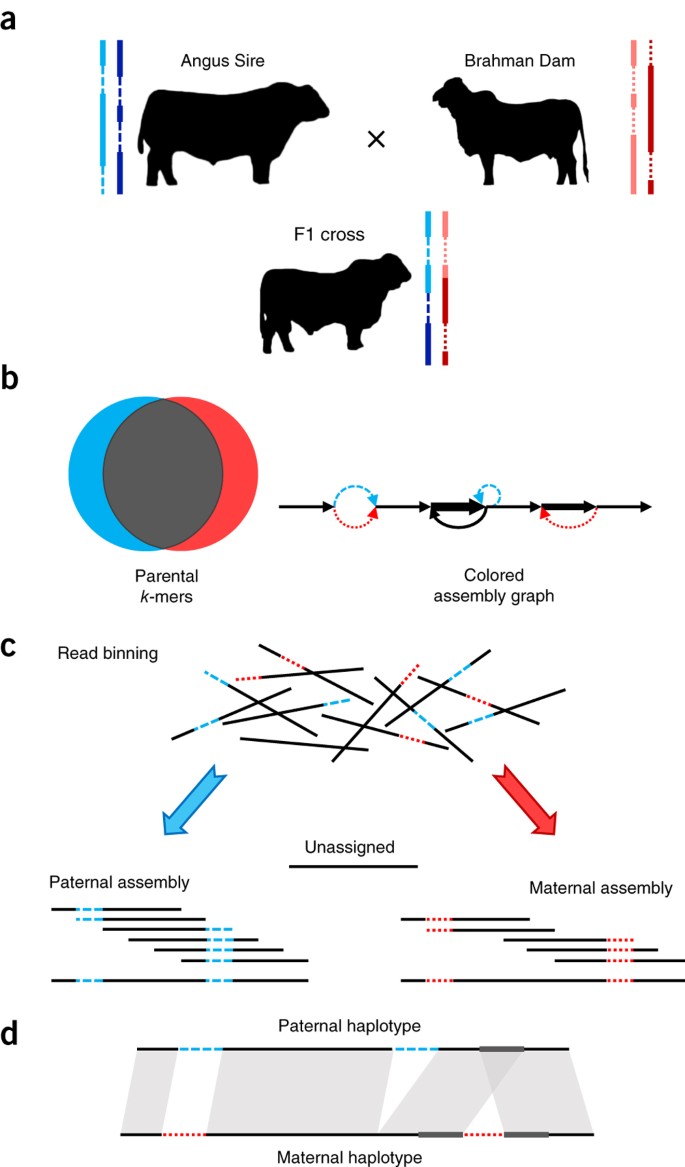
a、后代分别从两个亲本各继承一个重组单倍型。
b、两个亲本的 illumine 短读测序识别出特异性的 k-mers;从而推断出子代二倍体基因组中杂合等位基因的起源。
c、根据之前从亲本得到的特异性 k-mers,将 F1 pacbio 长读划分成两个单倍型集合,即 Paternal/Maternal;而后将每个单倍型单独组装,不受杂合变异的干扰。
d、生成的组装代表基因组规模的单倍型,并准确的恢复点突变和结构变异。
References
[1] Koren, S., Rhie, A., Walenz, B. et al. De novo assembly of haplotype-resolved genomes with trio binning. Nat Biotechnol 36, 1174–1182 (2018). https://doi.org/10.1038/nbt.4277